OpenAI、フラグシップモデル「GPT-4o」を発表。人間並みのスピードで音声入力情報に反応できる
末にある「o」は「Omni」の頭文字。音声・視覚・テキストをすべてリアルタイムで処理
OpenAIは5月14日、ChatGPTの新しいフラグシップモデル「GPT-4o」を発表した。末にある「o」は「Omni」の頭文字だという。
GPT-4oは音声、視覚、テキストの各種入力情報に対応しており、それぞれの形で出力できる。音声入力は232ミリ秒で、平均で320ミリ秒で反応できる。これは人間が会話における反応速度と同程度。英語とコードのパフォーマンスはGPT-4 Turboと同等で、英語以外の言語も高速化を実現している。
GPT-4oは順次展開される予定。テキストと画像の機能は本日よりすべてのユーザーに提供される。音声モードのアルファ版は今後数週間以内にChatGPT Plusユーザー向けに提供する。
Say hello to GPT-4o, our new flagship model which can reason across audio, vision, and text in real time: https://t.co/MYHZB79UqN
Text and image input rolling out today in API and ChatGPT with voice and video in the coming weeks. pic.twitter.com/uuthKZyzYx
— OpenAI (@OpenAI) May 13, 2024
もっと読む
2025.10.24
2025.02.13
2024.05.14
2024.05.13
2023.03.15

まだコメントはありません
最初のコメントを書いてみませんか?
コメント(0件)
注意点
「テック全般」新着記事

Netflix、米国でまた値上げ。スタンダードが2023年のプレミアムと同額になってしまう
2026.03.27
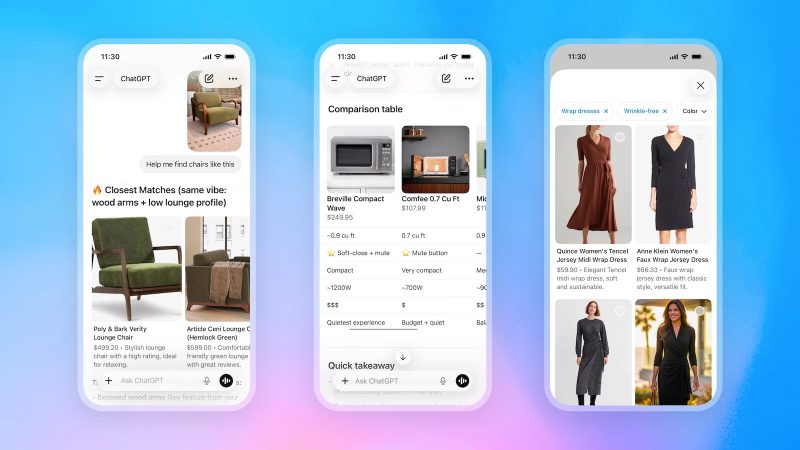
ChatGPT、今週からショッピング機能を大幅アップデート。全プラン対象で順次提供
2026.03.26
OpenAIのAI動画アプリ「Sora」、たった半年でサービス終了へ。Disneyとの大型契約も白紙に
2026.03.25

OpenAI、Mac向け”スーパーアプリ”を開発中か。ChatGPT・Codex・Atlasを1つに統合へ
2026.03.21
EngadgetがYahooの手を離れ、Static Mediaに売却されるらしい
2026.03.04

Claudeが米App Storeで突如1位になった理由。新機能ではなく”政府への反論”
2026.03.02
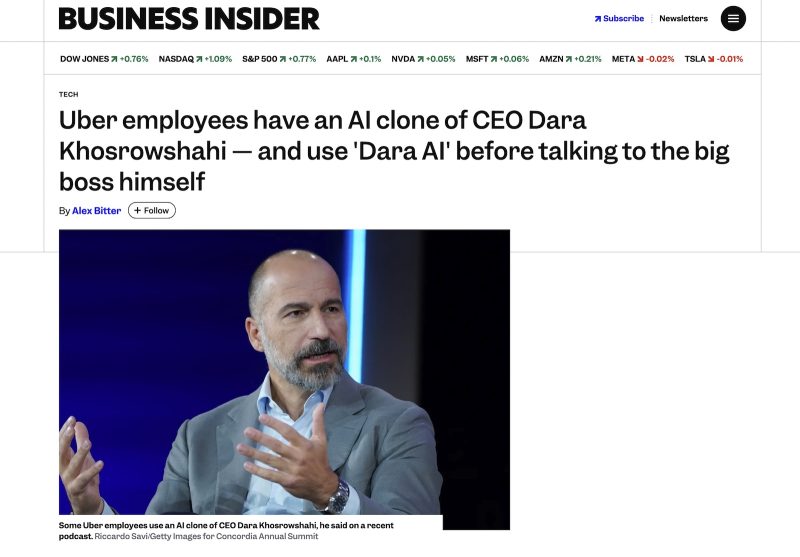
UberのCEO、”自分のAIクローン”で社員がプレゼン練習してると明かす
2026.02.25

Nothing自身が待ちきれない説。「Phone (4a)」、発表3日前にリアデザインをフライング公開
2026.02.24

メイウェザーとパッキャオ、11年ぶりのリマッチが決定。9月19日にNetflixが独占配信
2026.02.24

ChatGPTに広告が出てた。会話の最初からすぐ表示されるらしい
2026.02.20

Claude Sonnet 4.6が登場。無料ユーザーも初めてSonnetクラスがデフォルトに
2026.02.18
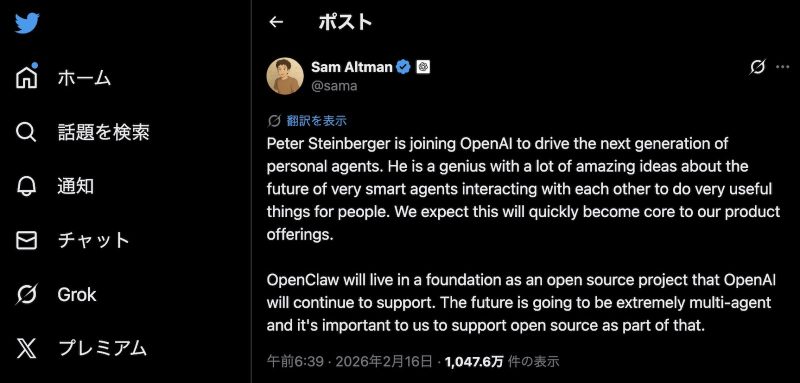
OpenClaw開発者がOpenAIに入社、次世代パーソナルエージェント開発へ
2026.02.16
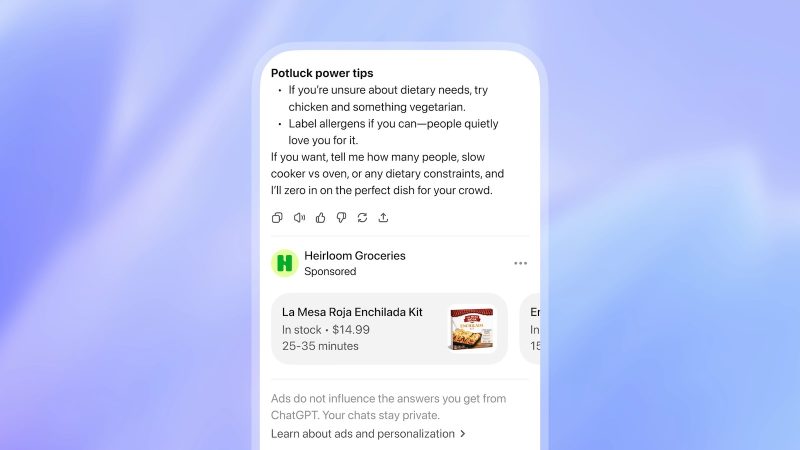
ChatGPT、米国で広告配信テスト開始──FreeとGoプランが対象、回答への影響はなし
2026.02.10
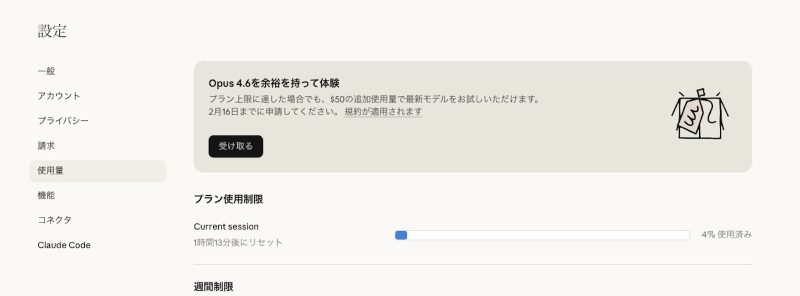
Anthropic、Claude ProとMaxユーザーに50ドル分の無料クレジット配布中!とりあえず今すぐもらっておけ!
2026.02.06
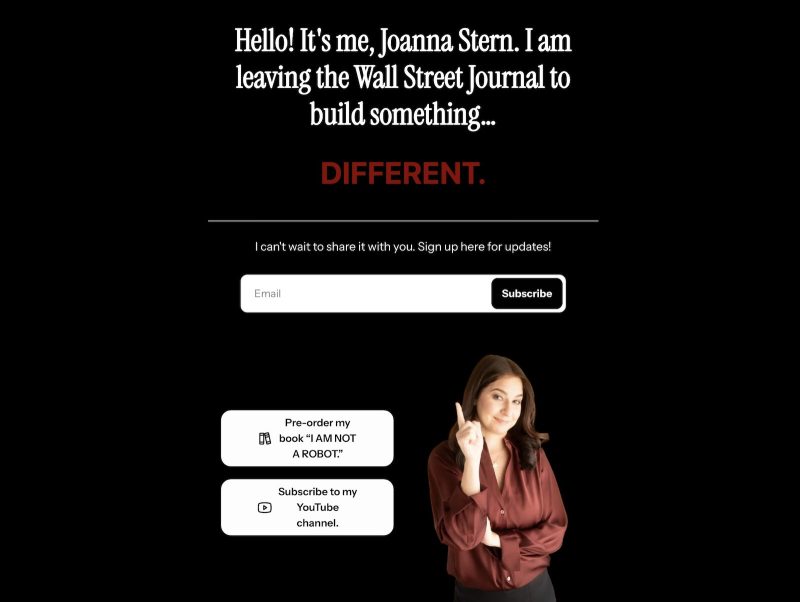
WSJの名物テック記者Joanna Sternさんが独立を発表!12年の在籍を経て自身のメディア企業を立ち上げへ
2026.02.06
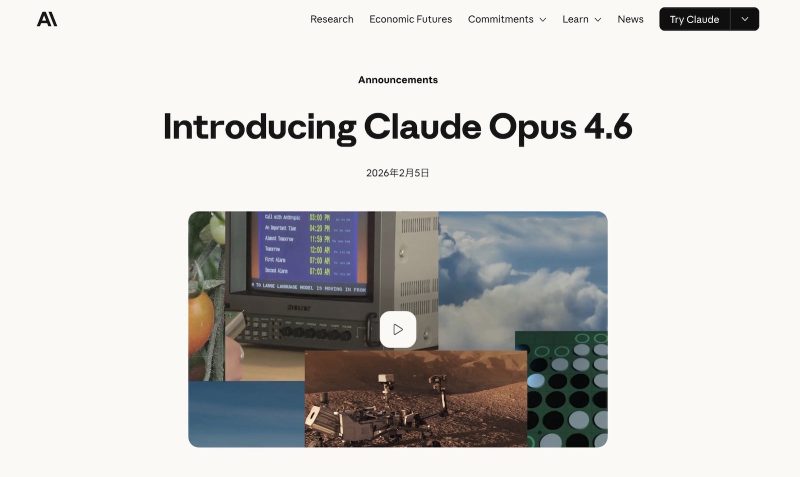
Anthropic、最上位AIモデル「Claude Opus 4.6」発表——GPT-5.2を上回る性能で100万トークン対応
2026.02.06

OpenAI CEOがAnthropicを猛批判、「明らかに不誠実」「権威主義的」と痛烈反論
2026.02.05

AnthropicがOpenAIとの違いを強調、スーパーボウルCMで「Claudeは広告なし」
2026.02.05

OpenAI、ライバルのAnthropicから安全対策の専門家を引き抜き──アルトマンCEO「今夜はぐっすり眠れそう」
2026.02.04

Fitbit創業者、今度は「家族全体の健康」を見守るAIサービスを立ち上げたらしい
2026.02.04